1764번: 듣보잡
첫째 줄에 듣도 못한 사람의 수 N, 보도 못한 사람의 수 M이 주어진다. 이어서 둘째 줄부터 N개의 줄에 걸쳐 듣도 못한 사람의 이름과, N+2째 줄부터 보도 못한 사람의 이름이 순서대로 주어진다.
www.acmicpc.net
N과 M의 최댓값이 500,000으로 매우 크기 때문에 일반적인 탐색으로는 제한 시간내에 정답을 구할 수 없다.
따라서 이분 탐색으로 원소를 찾도록 구현해야 한다.
c++ STL에 정의된 Set 컨테이너를 사용하면 쉽게 구현할 수 있다.
Set 컨테이너는 균형 이진 트리로 구현되어 있으므로 원소를 추가하면 자동으로 정렬되며, 원소를 로그 시간으로 찾을 수 있다는 특징이 있다.
Set을 통해 구현하는 것과 이분 탐색을 직접 구현하는 것 두가지 방법으로 구현하였다.
<Set 컨테이너 사용>
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
int main(void) {
int N, M;
cin >> N >> M;
set<string> personSet;
while (N--) {
string str;
cin >> str;
personSet.insert(str);
}
vector<string> result;
while (M--) {
string str;
cin >> str;
set<string>::iterator iter = personSet.find(str);
if (iter != personSet.end())
result.push_back(*iter);
}
sort(result.begin(), result.end());
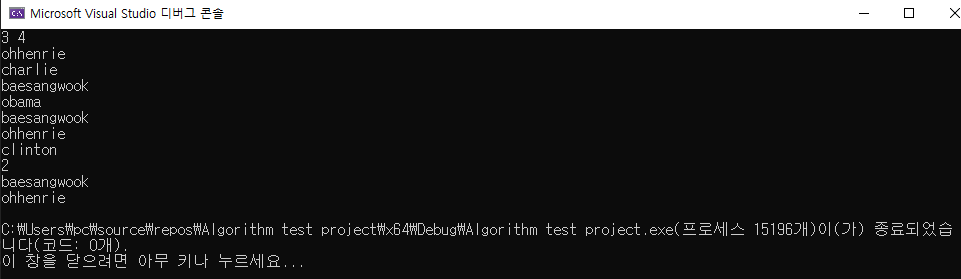
cout << result.size() << '\n';
for (auto x : result)
cout << x << '\n';
return 0;
}<Binary_search & sort 직접 구현>
#include <iostream>
#include <vector>
#include <set>
#include <algorithm>
using namespace std;
void swap(vector<string>& v, int idx1, int idx2) {
string temp = v[idx1];
v[idx1] = v[idx2];
v[idx2] = temp;
}
void swap(int arr[], int idx1, int idx2) {
int temp = arr[idx1];
arr[idx1] = arr[idx2];
arr[idx2] = temp;
}
int getMidIndex(vector<string>& v, int start, int end) {
int mid = (start + end) / 2;
int idx[3] = { start, mid, end };
if (v[idx[0]] > v[idx[1]])
swap(idx, 0, 1);
if (v[idx[1]] > v[idx[2]])
swap(idx, 1, 2);
if (v[idx[0]] > v[idx[1]])
swap(idx, 0, 1);
return idx[1];
}
void quick_sort(vector<string>& v, int left, int right) {
if (left >= right) return;
int pIdx = getMidIndex(v, left, right);
swap(v, left, pIdx);
int pivot = left;
int low = left + 1;
int high = right;
while (true) {
while (low <= right && v[low] <= v[pivot])
low++;
while (high > left && v[high] >= v[pivot])
high--;
if (low > high)
break;
swap(v, low, high);
}
swap(v, pivot, high);
quick_sort(v, left, high - 1);
quick_sort(v, high + 1, right);
}
bool binary_search(vector<string>& personVector, string str) {
int start = 0;
int end = personVector.size() - 1;
while (start <= end) {
int mid = (start + end) / 2;
if (personVector[mid] == str)
return true;
else if (personVector[mid] < str)
start = mid + 1;
else
end = mid - 1;
}
return false;
}
int main(void) {
int N, M;
cin >> N >> M;
vector<string> personVector;
while (N--) {
string str;
cin >> str;
personVector.push_back(str);
}
quick_sort(personVector, 0, personVector.size() - 1);
vector<string> result;
while (M--) {
string str;
cin >> str;
if (binary_search(personVector, str)) {
result.push_back(str);
}
}
quick_sort(result, 0, result.size() - 1);
cout << result.size() << '\n';
for (auto x : result)
cout << x << '\n';
return 0;
}
'알고리즘 > BOJ' 카테고리의 다른 글
| 백준 7569번: 토마토 (0) | 2023.08.18 |
|---|---|
| 백준 5430번: AC (0) | 2022.10.15 |
| 백준 4963번: 섬의 개수 (0) | 2022.10.15 |
| 백준 11724번: 연결 요소의 개수 (0) | 2022.10.15 |
| 백준 1697번: 숨바꼭질 (1) | 2022.10.15 |